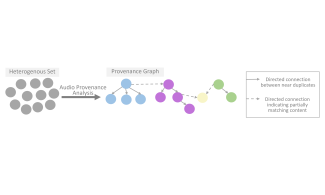
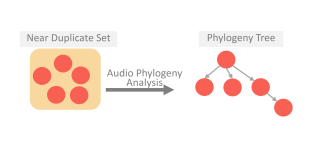
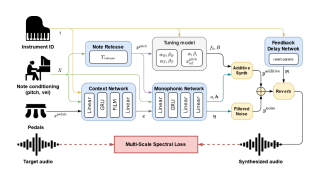
Technical Categories
AI services
Audio processing
Automated reasoning
Commonsense reasoning
Computer vision
Connected and automated vehicles
Machine learning
Multi-agent systems
Optimisation
Robotics and automation
Business Category
Cloud, Edge and Infrastructure
Earth Observation
Energy
Healthcare
Manufacturing
Telecommunications
Transportation
Organisation type
Company
Logiicdev GmbH