Asset Type
Docker container
I-NERGY Trusted Data Sharing
An easy to use tool to manage B2B Cross-stakeholder Trusted Off-chain Data Sharing
Welcome to the AI Assets Catalog! Here you can browse, search and download all the assets currently indexed in the AI-on-Demand platform, including AI libraries, datasets, containers, and more. You are welcome to publish your own AI assets here! To do so, log in in to the platform, go to your dashboard and use the Submit new content button to access the submission forms.
An easy to use tool to manage B2B Cross-stakeholder Trusted Off-chain Data Sharing
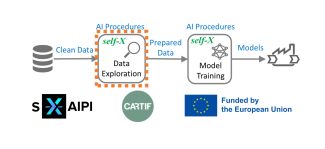
self-X autonomic supervised and unsupervised feature selection
Datasets of the LeQua 2024 Learning to Quantify Data Challenge
Cross-lingual Text Classification (CLC) consists of automatically classifying, according to a common set C of classes, documents each written in one of a set of languages L, and doing so more accurately than when “naïvely” classifying each document via it...
The Interactive Classification System (ICS), is a web-based application that supports the activity of manual text classification, i.e., labeling documents according to their content.
This data set comprises a labelled training set used in the experimentation of the paper "Binary Quantification and Dataset Shift: An Experimental Investigation".
Word-Class Embeddings (WCEs) are a form of supervised embeddings specially suited for multiclass text classification. WCEs are meant to be used as extensions (i.e., by concatenation) to pre-trained embeddings (e.g., GloVe or word2vec) embeddings in order ...
ql4facct is a software for replicating experiments concerning the evaluation of estimators of classifier "fairness".
This data set comprises a labeled training set, validation samples, and testing samples for ordinal quantification. It appears in our research paper "Ordinal Quantification Through Regularization", which we have published at ECML-PKDD 2022.