Asset Type
As a Service
DIH4AI: I-PRAG-5 Simulation and digital twinning for industrial systems
Advanced automated design of simulation models and their use of soft-sensors
Welcome to the AI Assets Catalog! Here you can browse, search and download all the assets currently indexed in the AI-on-Demand platform, including AI libraries, datasets, containers, and more. You are welcome to publish your own AI assets here! To do so, log in in to the platform, go to your dashboard and use the Submit new content button to access the submission forms.
Advanced automated design of simulation models and their use of soft-sensors
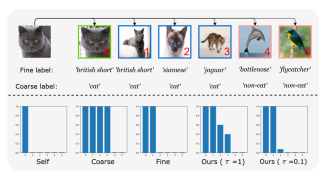
A masked contrastive learning framework for learning meaningful fine-grained representations with coarse-labeled dataset.
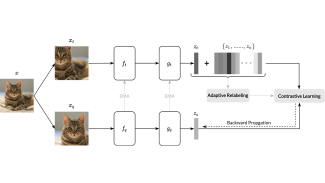
A self-supervised learning method aiming to alleviate the inherent false-negative problem in contrastive learning framework.
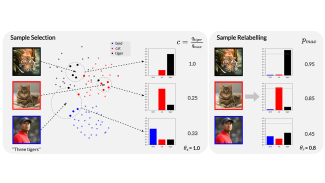
A robust and efficient training framework tackling with dataset with noisy labels.
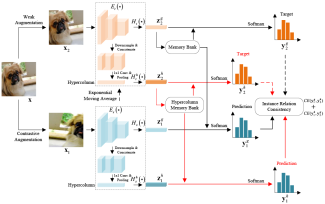
A self-supervised pre-training method with focus on alleviating class collision problem using a cross-context learning scheme.
A CLIP-based visual-language model called DFER-CLIP for in-the-wild dynamic facial expression of emotion recognition.

Leverages the association between parts of speech and specific visual modes of variation to better separate representations of style from content in the CLIP representations
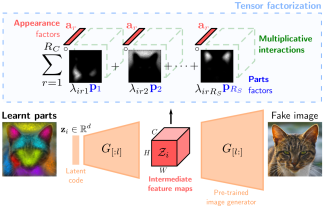
Localized image editing through joint factorization of parts of appearances in pre-trained GANs.
A neural network-based time-series forecasting model for concentrations of an electrochemical reaction.
The Aristotle University of Thessaloniki (hereinafter, AUTH) created the dataset ‘3D-Flood’, within the context of the project TEMA that was funded by the European Commission-European Union [Grant Agreement number: 101093003; start date: 01/12/2022; end d...